
합성곱 신경망
Limitation of DNN
- DNN
- 2D 데이터를 1D로 평탄화하여 DNN 적용 가능
- 위치에 상관없이 동일한 수준의 중요도를 가짐
==> 전체 글자가 2픽셀 이동만 하더라도 새로운 학습 데이터로 처리
==> translation invariance 특성이 보장 X
==> scale, ratation, dictortion invariance 특성 보장 X
- DNN = Multi-layer Perceptron = Feedforward NN = Fully Connected Layer (FC)
- Summary of Limitation
1) 학습시간
==> 크기, 회전, 이동 등 모든 데이터를 학습해야함
2) DNN 모델의 크기
3) 변수의 개수
==> 입력 영상이 커지고 Layer가 깊어지면 모델의 크기가 커지고 파라미터 수도 많아짐
Convolutional Neural Networks (CNN)
- CNN
- 합성곱 신경망(Convolutional neural network, CNN)은 시각적 이미지를 분석하는 데 사용되는 깊은 인공신경망의 한 종류
- CNN은 변환 불변성 특성에 기초하며, 이미지 및 비디오 인식, 추천 시스템, 이미지 분류, 의료 이미지 분석에 응용됨
==> DNN의 한계인 scale, rotation, distortion에 대한 특성 보장!!
- CNN은 다른 이미지 분류 알고리즘에 비해 상대적으로 전처리를 거의 사용하지 않음.
= 네트워크가 기존 알고리즘에서 수작업으로 제작된 여러 필터 역할을 스스로 학습함.
- Convolution + Neural Network
- CNN => Convolution 특성을 살린 신경망 연산
- 2번 이상의 CNN : 입력영상뿐만 아니라 중간 Feature map에도 Convolution 적용
** 영상처리 or 컴퓨터비전에서의 Convolution이란?
==> 주로 filter연산에서 사용되며, 영상으로부터 특정 feature를 추출하고 싶을 때 사용
- Receptive Field(수용영역)란?
- 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
- 외부 자극이 전체 영향을 끼치는게 아니라 특정 영역에만 영향을 미친다.
- 영상에서 특정 위치에 있는 픽셀들은 그 주변에 있는 일부 픽셀들과만 correlation이 높을 뿐이며, 거리가 멀어질 수록 그 영향은 감소하게 된다.
- kernel
- Advantage of CNN
- Conv layer는 형상을 유지한다
==> 평탄화 필요x
- 즉! 입/출력 모두 3차원 데이터로 처리하기 때문에 공간적 정보를 유지할 수 있다.

- example
32 x 32 x 3 image => 5 x 5 x 3 filters 6개 => 28 x 28 activation maps 6개
=> stack these up => get a new image of size 28 x 28 x 6
- stride == 1 : 필터가 1칸씩 이동
ex) 7 x 7 input(spatially) assume 3 x 3 filter => 5 x 5 output
output size : (N-F)/stride + 1
- pad : (F-1)/2
==> pad 이용해서 영상 사이즈를 유지할 수 있음
- Summary
- Accepts a volume of size W1 x H1 x D1
- requires four hyperparameters:
1) Number of filters : K
2) their spatial extent : F
3) the stride S
4) the amount of zero padding P
- Produces a volume of size W2 x H2 x D2
1) W2 = (W1 - F + 2P) / S + 1
2) H2 = (H1 - F + 2P) / S + 1
3) D2 = K
Pooling
: Feature Map을 resizing 하는 것
==> 더 높은 정확도를 위해서는 필터가 많아야 하지만, 필터가 늘어날수록 feature map이 늘어남. 이는 딥러닝 모델의 dimension이 늘어난다는 것이고, high dimension 모델은 그만큼 파라미터의 수 또한 늘어남. 이는 overffing의 문제점 뿐만 아니라, 모델의 사이즈와 레이턴시에도 큰 영향을 미침
==> 따라서 차원을 감소시켜야한다!!
ex. max pooling, average pooling
- Max pooling
- Filter 내에서 가장 큰 값을 선택
=> average pooling은 spatial structure를 보존하되 이미지가 smooth해짐
=> max pooling은 더 강한 특징만 남기는 방식
- depth를 줄이지 않고 spatially하게만 줄임(height & width)
32 x 32 x 3 → 16 x 16 x 3
- Convolution layers : 데이터를 특성을 살림
- visualization of activation map(feature map) : 입력 영상이 convolution layer를 지났을 때 결과물
- pooling layer(sampling) : resize feature map
- fully connected layer(FC layer) : 각 라벨에 대한 최종확률을 제공
CNN 영상 분류기
MNIST 데이터 셋에 대해 LeNet이 가장 높은 성능을 보임
- LeNet5
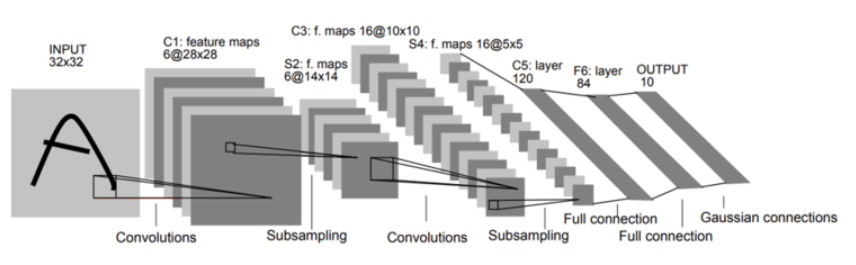
==> Convolution과 Subsampling 과정을 반복적으로 거치면서, 마지막에 Fully-connected Multi-layered Neural Network로 분류를 수행
- Lenet5 단계
- C1 : 5x5 convolution을 연산하여 28x28 사이즈의 6개의 feature map을 생성
자유파라미터 수 : 5*5(convolution kernel) + 1(bias) = 26
* bias는 필터를 적용한 후에 더해주게됨(feature map의 전체 밝기를 조절하는 것으로 볼 수 있음)
- S2 : subsampling을 하여 feature map의 크기를 14x14로 줄임
자유파라미터 수 : {1(weight) + 1(bias)}*6(feature map) = 12 <= 각각의 feature map마다 average pooling을 수행
- C3 : 5x5 convolution을 연산하여 10x10사이즈의 16개의 feature map을 생성.
이 때! 6개의 feature map을 모든 출력에 연결하지 않고, 아래 표와 같이 선택적으로 입력 영상을 골라 출력 영상과 연결.
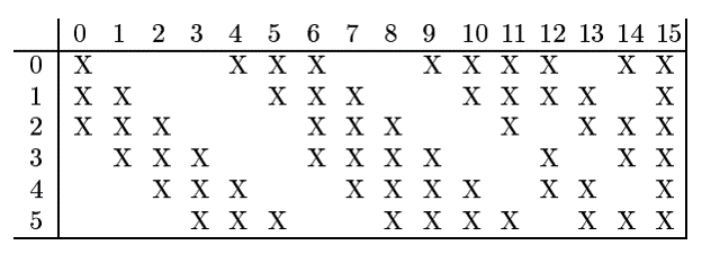
=> 연결의 symmetry를 깨줌으로써, 처음 concolution으로부터 얻은 6개의 low-level feature가 서로 다른 조합으로 섞이면서 global feature로 나타나기를 기대하기 때문
자유파라미터 수 : 25(kernel)x50(s2와 c3의 연결 개수) + 16(bias)
- S4 : subsampling을 하여 feature map의 크기를 5x5로 줄임
자유파라미터 수 : {1(weight) + 1(bias)}*16(feature map) = 32 <= 각각의 feature map마다 average pooling을 수행
- C5 : 5x5 convolution을 연산하여 1x1사이즈의 120개의 feature map을 생성
자유파라미터 수 : 25(kernel)x16(s4의 feature map 수)x120(c5의 feature map 수) + 120(bias) = 48120 <= S4의 모든 feature map이 c5의 모든 feature map과 연결
- F6 : Fully-connected neural network로 c5의 결과를 84개의 unit에 연결
자유파라미터 수 : 120(c5)x84(f6)x84(bias)=10164

- 전이 학습(Transfer learning)
- 이미 학습된 신경망의 능력을 유사하거나 전혀 새로운 분야에서 사용되는 신경망의 학습에 이용하는 것
- 높은 정확도를 비교적 짧은 시간 내에 달성할 수 있기 때문에 컴퓨터 비전 분야에서 유명한 방법론에 해당함
- 컴퓨터 비전에서 말하는 전이 학습은 주로 사전 학습된 모델을 이용하는 것을 뜻함
- 사전 학습된 모델(Pretrained Model)
- 내가 풀고자 하는 문제와 비슷하면서 사이즈가 큰 데이터로 이미 학습이 되어 있는 모델
- 네트워크가 이미지를 분류하는데 있어서 주요한 특징들을 학습하기 위해서는 대량의 데이터셋이 필요
ex. ImageNet
- 큰 데이터로 모델을 학습시키는 것은 오랜 시간과 연산량이 필요하므로, 관례적으로는 이미 공개 되어있는 모델들을 그저 import해서 사용

- ex
