
ggoggo
5.4 캐시 매핑 방식 본문
1. 캐시 등록정보
메인 메모리 용량 > 캐시 용량(capacity) 이므로 메인메모리는 데이터 블록으로 나누어져 다수의 데이터 블록들이 캐시를 공유해 사용함. 메인메모리와 캐시 사이의 전송은 데이터 블록 단위임.
→ 데이터 블록 하나는 여러 개의 워드로 구성됨. (워드 크기 = 메모리 주소 하나에 할당되는 비트 수, 주로 1바이트 사용)
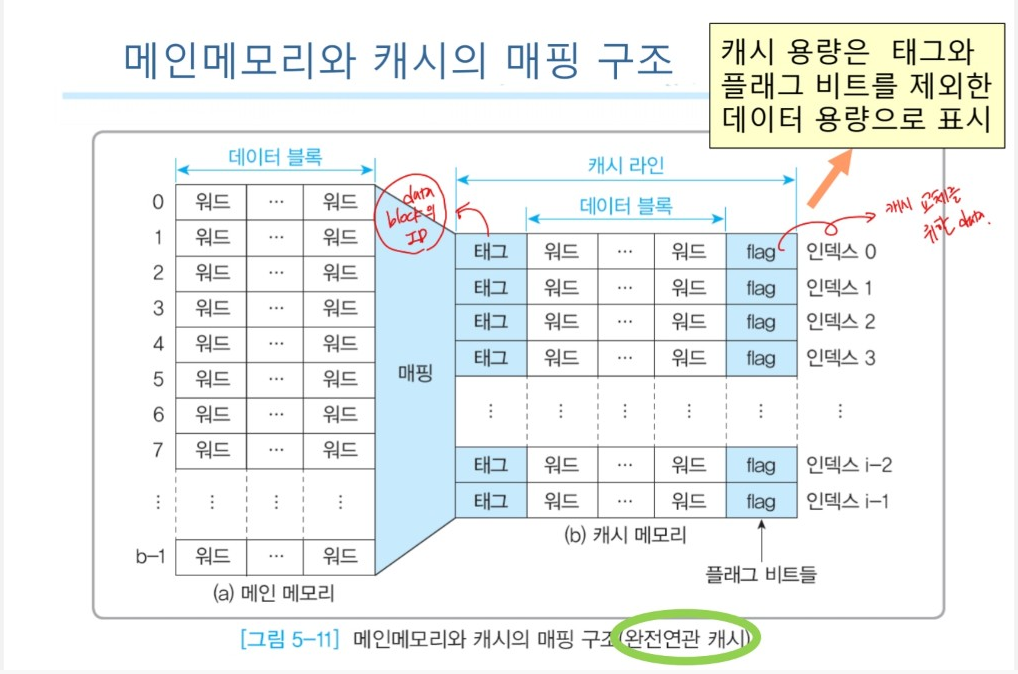
- 캐시라인
- 캐시 메모리를 구성하는 행(row)
- 메인메모리의 데이터 블록 중 하나를 저장
- 캐시의 데이터 교체는 캐시라인 단위
- 캐시메모리 구조
1) 인덱스(index) : 캐시에서 몇 번째 캐시 라인인지 구분하는 색인 번호
2) 캐시 라인 등록정보
: 메인메모리에 있는 하나의 데이터 블록이 하나의 캐시 라인으로 복사되면 해당 캐시라인에 <등록정보> 생성
: 복사를 요청한 메인메모리 데이터블록 위치정보로 태그(tag) 포함
: 현재 저장되어 있는 데이터 블록이 유효한지 아닌지를 표시하기 위한 플래그(flag) 비트 포함
: Instruction Cache에는 Valid flag bit, Data Cache에는 Valid flag bit와 Dirty flag bit
CPU가 요청한 메인메모리 주소로 캐시를 확인 -> 발견 = 캐시 적중, 실패 = 캐시 실패
2. 캐시의 매핑
메인 메모리에 있는 다수의 데이터 블록들이 소수의 캐시 라인을 공유하는 방법
CPU가 발생시킨 메인메모리 주소와 캐시 라인 자료를 1:1로 매핑
- 캐시의 매핑 방식
1) 완전연관(fully associative) 캐시 : 메인메모리의 데이터 블록이 아무 캐시 라인에나 들어감
2) 직접매핑(direct-mapped) 캐시 : 데이터 블록이 지정된 캐시 라인에만 들어감
3) 세트연관(set-associative) 캐시 : 데이트 블록이 복수의 캐시 라인을 묶은 지정된 세트에만 들어감
3. 완전연관 캐시
메인메모리의 데이터 블록이 모든 캐시 라인에 들어감
→ CPU가 발생시킨 메인메모리 주소가 모든 캐시 라인에 포함된 블록 내의 워드로 매핑
- 완전연관 캐시의 메인메모리 주소 형식
1) 태그 필드 : 캐시 라인에 들어갈 메인메모리 블록 선택
2) 블록 오프셋 필드 : 블록에 포함된 워드를 선택
- 적중여부검사
(1) 메인메모리 주소의 태그와 일치하는 것 있는지 검사
(2) 적중 → 블록 오프셋 필드의 값을 이용해 해당 캐시 라인의 워드 중 하나를 골라 읽거나 쓴다.
실패 → 메인메모리에서 원하는 주소의 데이터를 읽거나 쓴다. 또한 새로사용된 메인메모리의 해당 블록을 '비어있거나 교체될 캐시 라인'에 넣어주고 태그 비트를 고쳐준다.

캐시용량 = 64word & 블록크기 = 2^2 = 4word
→필요 블록 오프셋 필드 = 2bit
8비트 메모리 주소
→태그 필드 = 8-2 = 6 bit
(메인메모리 용량) = (블록 수) x (블록 크기)
→64x4 = 256word
* 1word = 32bit = 4byte
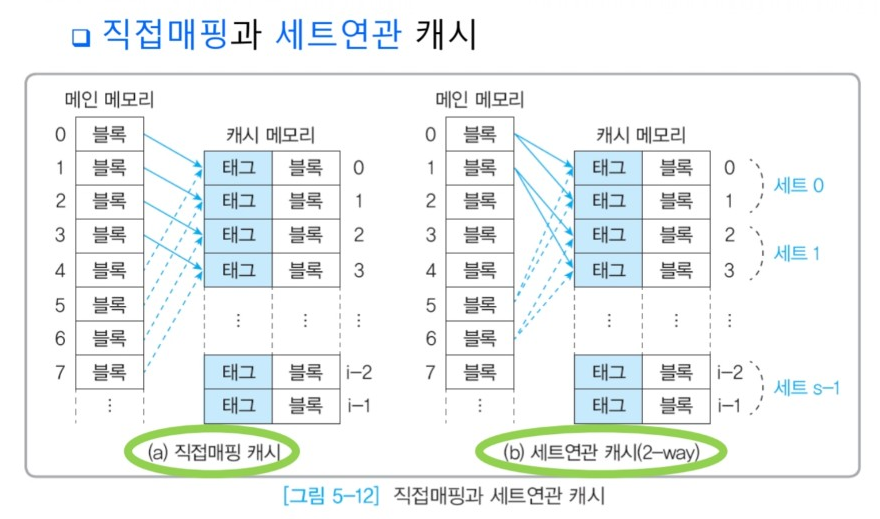
4. 직접매핑 캐시
메인메모리의 데이터 블록이 지정된 캐시 라인에만 들어감
→ CPU가 발생시킨 메인메모리 주소가 지정된 캐시 라인에 포함된 블록 내의 워드로 매핑
- 직접매핑 케시의 메인메모리 주소 형식
1) 인덱스 필드 : 캐시 라인을 선택
2) 태그 필드 : 캐시 라인에 들어갈 메인메모리의 블록을 선택
3) 블록 오프셋 필드 : 블록에 포함된 워드를 선택
- 적중여부 검사
(1) 인덱스 필드로 캐시 라인을 먼저 선택
(2) 선택된 캐시라이느이 태그를 조사해 메인메모리 주소의 태그 필드와 일티하는지 검사
(3) 적중 → 블록 오프셋 필드의 값을 이용해 해당 캐시 라인의 워드 중 하나를 골라 읽거나 쓴다.
실패 → 메인메모리에서 우너하는 주소의 데이터를 읽거나 쓴다, 또한 새로 사용된 메인메모리의 해당 블록을 '지정된 캐시 라인'에 넣어주고 태그 비트를 고쳐준다.

캐시용량 = 64word, 블록크기 2^4 => 4word
→ 블록 오프셋 필드 2비트 필요
(캐시 라인 수) = (캐시 용량) / (블록 크기)
→ 인덱스 필드에 4비트 필요
8비트 메모리 주소 → 태그 필드는 8-4-2 = 2비트
캐시가 지원하는 총 (블록 수)는 최대
→ (캐시 라인 당 블록 수) x (캐시 라인 수) = 4 x 16 = 64
(메인메모리 용량) = (블록 수) x (블록 크기)
→ 최대 64x4=256word
5. 세트연관 캐시
메인메모리의 데이터 블록이 복수의 캐시 라인을 묶은 지정된 세트에만 들어감
→ CPU가 발생시킨 메인메모리 주소가 지정된 세트에 포함된 블록 내의 워드로 매핑
- 세트연관 캐시의 메인메모리 주소 형식
1) 세트 필드 : 세트를 선택
2) 태그 필드 : 캐시 라인에 들어갈 메인메모리의 블록을 선택
3) 블록 오프셋 필드 : 블록에 포함된 워드를 선택
- 적중여부 검사
(1) 세트 필드로 세트를 먼저 선택
(2) 선택된 세트 내의 모든 캐시 라인의 태그를 조사해 메인메모리 주소릐 태그 피드와 일치하는 것이 있는지 검사
(3) 적중 → 블록 오프셋 필드의 값을 이용해 해당 캐시 라인의 워드 중 하나를 골라 읽거나 쓴다,
실패 → 메인메모리에서 원하는 주소의 데이터를 읽거나 쓴다. 또한 새로 사용된 메인메모리의 해당 블록을 '지정된 세트에서 비어있거나 교체될 캐시 라인'에 넣어주고 태그 비트를 고쳐준다.

캐시용량 = 64워드, 블록 크기 = 2^4 = 4워드
→ 블록 오프셋 필드 2비트 필요
캐시 라인 수 = 캐시 용량 / 블록 크기
→ 64/4 = 16개
8비트 메모리 주소 → 태그 필드는 8-3-2=3비트
캐시가 지원하는 총 블록 수는 최대
→ (세트 당 블록 수)x(세트 수)=8x8=64개
(메인메모리 용량)=(블록 수)x(블록 크기)
→ 64x4=256워드
- 세트연관 캐시 방식의 종류
1) 2-방향 세트연관 캐시 : 각 세트가 2개의 캐시 라인을 갖는 경우
2) n-방향 세트연관 캐시 : 각 세트가 n개의 캐시 라인을 갖는 경우
- 연관도(associativity)
세트를 구성하는 way 수 n : (세트 수) = (캐시 라인 수)/(way 수)의 관계
캐시 전체가 하나의 세트가 되면 완전연관 캐시
연관도↑ → 하드웨어 복잡해짐
6. 캐시 매핑 방식 비교
교체 정책과 매핑의 연관도는 균형을 선택해야함
- 연관도가 클수록 세트 내에 조사해야 할 캐시 라인 수 가 늘어나 하드웨어가 복잡하고 시간이 많이 걸림
- 연관도 클수록 복잡하나 적중률은 좋은 성능
- Fully-Associative(완전연관) 캐시
캐시 라인 선택이 자유롭다
장 : 반복적인 서브루틴이나 배열 등 연속적인 블록이 적재될 때 지역성이 좋아져 적중률이 매우 높아짐
단 : 등록정보가 많아지면 태그를 비교하는 하드웨어를 설계하는 노력이 많이 들고 복잡해짐
- Direct-mapped(직접매핑) 캐시
오직 한군데 캐시 라인으로 감
장 : 선택의 여지가 없어 교체정책 필요 없음
→ 캐시 적중검사도 간단하고 가장 빠른 실행이 가능하고, 구조가 간단해 회로 비용이 적게 듦
단 : 한 캐시 라인을 공유하는 블록 중에서 반복적으로 교체할 일이 생기면 적중률 크게 떨어짐
→ 크기가 무척 커야 상당한 성능을 얻을 수 있고 다른 방식보다 예측이 더 불가능
- Set-associative(세트연관) 캐시
두 방식의 장단점을 결합
장 : 완전연관 캐시와 직접매핑 캐시의 장점 결합
단 : way 수가 늘어날수록 하드웨어가 점점 복잡
연관도가 클수록 캐시 실패율이 줄어 성능 좋아짐.(way증가시킬수록)
ex) 직접매핑 → 2-way 세트연관, 2-way → 4-way(캐시 적중률에서 캐시 용량을 2배로 늘린 효과)
n-way(n>4)이상은 그런 효과 작지만 가상주소 캐시의 일관성 문제에 유리
7. MMU와 TLB
<가상메모리를 메인메모리에 매핑하는 방법>
프로그램에 의해 발생하는 가상주소를 메인메모리에 있는 물리주소로 변환하는 과정 필요
→ 프로세서 칩에 내장된 MMU 장치가 TLB에 저장된 내용으로 이를 수행
- MMU(Memory Management Unit)
: 메모리 관리 장치. 물리주소 변환과 메모리 보호가 주요 역할
메모리 접근권한을 제어해 메모리를 보호하고 캐시 관리, 버스 중재 등의 역할도 수행
- TLB(Translation Looaside Buffer)
: 변환 색인 버퍼. 가상주소로 이에 해당하는 물리주소를 걸색할 떄 사용되는 버퍼메모리
- 최근에 일어난 가상 메모리 주소와 물리 주소의 변환 테이블을 저장하는 일종의 주소 변환 캐시
- 페이지 테이블에 대한 일종의 캐시 역할
→ 운영체제가 저장해둔 페이지 테이블의 일부를 검색속도가 빠른 CPU 내부로 복사해온 것
→ 페이지 테이블 이용을 생략해 여러 메모리 내용을 읽고 물리주소를 계산하던 주소변환 시간을 줄일 목적
- TLB 내용은 메인메모리의 일부 페이지 프레임에 저장된 가상메모리의 일부 페이지를 표시한 정보
→ 각 항의 내용은 페이지 테이블처럼 하나의 페이지 번호가 하나의 페이지 프레임 번호로 1:1로 매핑

- TLB를 이용한 물리주소 변환
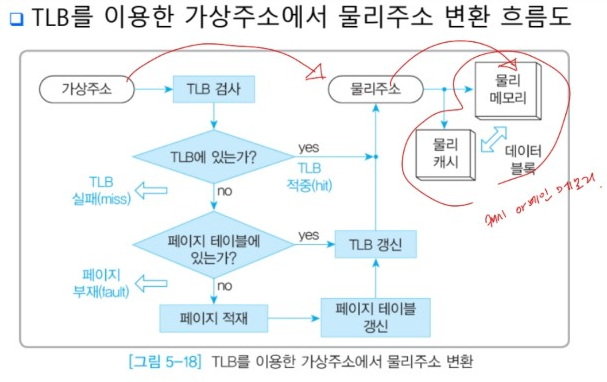
(1) CPU가 요청한 가상주소 발생
(2) TLB 검사
(3) TLB 적중 → 물리주소 변환
TLB 실패 → 페이지 테이블 검사
(4) 페이지테이블에 주소변환정보 존재o → TLB 갱신 -> 물리주소 변환
페이지테이블에 주소변환정보 존재x → page fault
**page fault : 가상주소 페이지가 메인메모리에 없는 경우
→ OS가 HDD에서 메인메모리로 새로운 페이지를 전송
→ 메인메모리에 빈 페이지 프레임이 있으면 새로운 페이지를 적재(load), 빈공간 없으면 기존 페이지와 교체
: 메모리 보호 목적으로도 사용
→ 허락받지 않은 프로그램이 접근하면 일부러 일으켜 차단
(5) page fault → 페이지 테이블 갱신 → TLB 갱신 → 물리주소 변환

8. 가상주소 캐시
물리주소로 변환한 캐시 값을 저장해 물리주소로 변환하는 시간을 더욱 줄여줌
- 가상주소 캐시의 동작
(1) 가상메모리를 사용하는 CPU는 MMU에 가상주소를 발생
(2) MMU는 가상주소 캐시를 먼저 확인
(3) 가상주소 캐시 안에 물리주소로 변환할 가상주소가 존재 → MMU가 물리주소를 그대로 가져다 사용
- 물리캐시가 캐시 적중 여부를 확인하는 시간을 줄임. ← 가상주소 캐시 사용하면 물리캐시의 적중여부 바로 확인 가능
원래, 적중여부를 확인하기 위해서는 TLB에서 가상주소를 물리주소로 변환하고 계산하는 과정이 필요
- 가상주소 캐시의 적중과 실패
CPU가 요청한 가상주소가 가상주소 캐시 안세어 발견 = 적중
→ MMU가 물리메모리의 검색 속도를 높임
실패
→ TLB확인
'3-1 > 컴퓨터구조 및 운영체제' 카테고리의 다른 글
| 운영체제 : Ch 1.3 Storage Management (0) | 2022.06.10 |
|---|---|
| 운영체제 : Ch 1.2 Overview of Computer System Structure (0) | 2022.06.10 |
| 5.3 캐시메모리 (0) | 2022.05.28 |
| 5.2 메모리 계층구조 (0) | 2022.05.12 |
| 5.1 기억장치 (0) | 2022.05.11 |



